關於加速機器學習,你需要知道的基本觀念
- 《給學弟妹的矽谷 AI / Software 指南》是一個矽谷工程師自發的眾籌寫作計劃,由源來適你社群推動。這將是一個在台灣軟體學生圈內很有影響力的文章系列。已有 >10 篇準備發布,目標 100 篇並出書,歡迎 tag 強者大神來寫!
在機器學習(ML)與人工智慧(AI)大爆炸的時代,究竟工程師是如何讓這些龐大複雜的程式在時間內運行完成? ChatGPT 或現今隨處可見的聊天機器人,又是怎麼在短時間內"思考"人類的提問、搜尋資料、並給出答案?我們將在這篇文章告訴你最基礎的加速 ML 的觀念!
基本背景知識 — 如何加速一個程式
在處理器中,有很多不同的資源,例如 ALU (Arithmetic Logic Unit) 是一個執行數學運算 (Compute) 的資源,DRAM (Dynamic Random Access Memory) 是一種 Memory,也是一種資源。每一個資源都有一個最快的運行速率,我們稱之為帶寬 (bandwidth),例如 Compute 的帶寬單位是每秒可以處理幾個浮點數的運算 (FLOPS, floating point operations per second), Memory 的帶寬單位是每秒可以讀取或寫入幾個 gigabytes (GB/s, gigabytes per second)。
理論上
理想上,任意一種程式在處理器上被運行的時候,所需花的時間為
時間 = max(工作量0/帶寬0, 工作量1/帶寬1, …, 工作量n/帶寬n)
"工作量0"表示需要用到"資源0"的工作量有多少,例如 Compute 上的工作量就是多少個浮點數運算,Memory 上的工作量就是總共需要讀/寫幾個 bytes。
“帶寬0"表示"資源0"的帶寬。
這個公式的概念為,針對每一個資源,根據需要用在該資源的工作量有多少,去除以該資源的帶寬,就可以得到該資源需要花多少時間處理這個工作量。一個處理器要運行一個程式需要花的時間,就是這個處理器上需要花最多時間的資源所花的時間。而這個需要花最多的時間的資源,我們稱為瓶頸資源(bottleneck)。
為了方便解釋,這裡我們假設處理器上就只有兩種資源,分別是 ALU(代表 Compute) 和 DRAM(代表Memory)。公式被簡化為
時間 = max(compute 工作量/compute 帶寬, memory 工作量/memory 帶寬)
當我們想要加速這個程式,也就是讓時間降低,以這個公式來看就只有兩種作法:
- 減少工作量
- 增加帶寬
增加帶寬理想上是不需要的,因為帶寬的定義為這個資源最快的運行速率,這在一個處理器上是固定的值,不會改變。
剩下的就是減少工作量了!但,究竟我們要怎麼知道該選擇 compute 還是 memory 來減少工作量呢?
當我們再看一次這個公式,我們會發現,這個公式可以被解讀為
compute 工作量 / memory 工作量 > compute 帶寬 / memory 帶寬 ? Compute: Memory
當不等式成立的時候,就要選擇 compute,不成立的時候,就要選擇 memory。這樣的過程可以為我們找到瓶頸資源(bottleneck),也就是前面提到的花最多時間的資源。接著,我們只要想出新的演算法來減少瓶頸資源的工作量,就可以達到加速程式的效果。
實務上
現實沒有理想中的世界那麼簡單。在現實中,處理器不會只有兩個資源。更重要的是,一個程式中的每個資源的工作量會彼此依賴 (dependent)。現在來想想一個簡單的程式:
c = a + b
當一個處理器要運行這個程式,它得先從某處提取出 a 和 b 的值,做完加法,再把結果存到 c。假設 a 和 b 的值都存在 memory 裡面的話,那麼這個加法就必須等到 memory 做完提取的工作才能執行。這時候,compute 這個資源沒辦法做任何工作,只能坐著乾等(我們稱這種情況為 stalling)。這樣一來,處理器運行這個程式所花的時間就再也不是理論上的公式這麼簡單了!
所以,實務上,我們運用的各種技巧 (technique) 大部分都是為了解決"資源坐著乾等"的問題。
如何加速ML
接下來,我們要來介紹幾個常用的技巧來加速 ML。其中有些技巧是通用(別種程式也適用),有些技巧是 ML 特定的,但他們都離不開我們兩個主要的方向: "減少工作量" 和 "不讓資源坐著乾等"。
減少工作量
KV Caching
在現在很紅的大型語言模型領域,其中一個很典型的優化技巧就是KV Caching。這裡的 caching 屬於軟體上的 caching,這個軟體會把已經運算過的結果存起來,使得下一次跑模型的時候不用再重新計算一次結果。這麼做大幅減少了語言模型需要運算的量,以及為了該運算所需讀取的資料量。
Batching
Batching 常見於所有的深度學習 (Deep Learning) 模型,從最早的 AlexNet 到現今的大型語言模型,是一個直觀且有效的優化。Batching 就是把通過模型的每一個獨立的資料點組合 (batch) 起來,讓該模型同時處理多個資料點。相較於一次只處理一個資料點,batching 讓處理器只需要讀取模型一次,就可以運算多個資料點,大量省下了讀取模型的工作量。
不讓資源坐著乾等
Pipelining
Pipelining 是一種通用的優化技巧。其概念為將一段程式切成好幾個小段,讓第二個資源在第一個資源做完第一小段的工作之後就可以開始工作。
以一個實際的例子說明,假設我們今天要做向量加法 (C = A + B) ,一般我們會這樣寫:

如果沒有優化,這個程式實際執行的時候可能會像這樣:

這個加法運算會等到 A 和 B 這兩個向量全都讀取進來才開始做。但實際上,index=0 的加法在 A[0] 和 B[0] 讀進來之後就已經可以做了。
運用 pipelining 的技巧,我們可以把 load A 切成好幾個小段讓加法可以快點開始做:
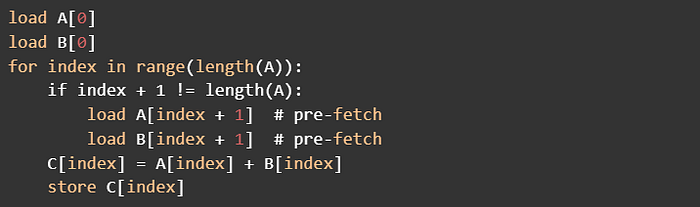
這樣的寫法不僅可以讓加法快點開始做,也可以在做加法的同時先讀取下次加法的資料,這樣 compute 和 memory 就不會常常互相等對方了!
Layer fusion
Layer fusion 也常見於所有深度學習模型。顧名思義,這個做法就是把模型裡兩個本來是不一樣的 layer 合在一起變成一個 layer。通常使用的情境是當這兩個 layer 的瓶頸資源不同,且這兩個 layer 的工作量沒有彼此依賴時。這時把 layer 合在一起後,因為瓶頸資源不同,這兩個 layer 的工作量可以同時被處理而不互相干擾,使資源不被浪費。(也就是緩和了 memory 在 compute 為瓶頸的時候會乾等,以及 compute 在 memory 為瓶頸的時候會乾等的問題。)
延伸
現在的 ML 模型越來越大,很多模型已經再也無法放進一個處理器來執行,而是需要多個處理器合作執行。這又會衍伸其他問題,像是處理器之間要怎麼同步資訊。這個同步的過程不只會增加工作量,還有可能會增加資源坐著乾等的機率。這部分展開來又會是一個長篇,這裡就不贅述,有興趣的話可以去搜尋各種 parallelism 的技巧,例如"Tensor Parallelism"。
工作內容
基本上就是結合深度學習的知識和前面描述的分析如何加速 ML 的知識,來優化軟體與硬體。軟體方面通常就是設計演算法,硬體方面是參與下一代硬體架構的研究。有 computer architecture 的背景知識會巨大加分。工作範圍很廣,而且每天都在變化,模型在快速迭代,所以掌握基礎知識並應用到新的模型是工作中的主要挑戰。
以下是我的公司關於這個職缺的描述:
Job Description
- Develop innovative architectures to extend the state of the art in deep learning performance and efficiency (下一代硬體架構研究)
- Prototype key deep learning and data analytics algorithms and applications (設計軟體演算法)
- Analyze performance, cost and power trade-offs by developing analytical models, simulators and test suites (使用模擬來預測 ML 的執行速度,可以用來研究下一代硬體架構和設計軟體演算法)
- Understand and analyze the interplay of hardware and software architectures on future algorithms, programming models and applications (下一代硬體架構研究以及中長期的演算法研究)
- Actively collaborate with software, product and research teams to guide the direction of deep learning HW and SW (和軟體產品部門以及硬體產品部門合作,我工作上實際接觸到的部門遠遠不止這些)
職涯發展
我是從修 Computer Architecture 、 Parallel Computer Architecture 、 Parallel Programming 這些課程進入這個領域的。後來把這個領域的知識用在 ML,但有 Computer Architecture 的基礎知識的話,要應用在甚麼領域真的非常彈性,可以依照自己喜好選擇想要加速的領域,例如 gaming (graphics) 或 science (物理、化學、生物、氣候變遷等等)。應用範圍非常廣,可以跨領域和該領域專業的人合作,這是我非常喜歡這個領域的地方。
另一個我喜歡這個領域的地方是它介於軟硬體之間。加速程式可以從硬體著手也可以從軟體著手。甚至軟體的發展趨勢會影響硬體的開發。跨領域的專業使得職涯發展較有彈性,可以依照自己的喜好選擇想要發展/鑽研的方向,同時也可以分別和專精軟體專業或專精硬體專業的人合作,從他們身上學習知識,非常有趣。
我大學時在台大幾乎沒有教授在做相關的領域,當時只有資工系的楊佳玲老師開的電腦架構的課。不確定現在台灣有沒有更多教授投入。線上課程搜尋上面列的三個關鍵字都可以找到很多課程來學習。
找工作的話,往硬體的方面,除了 NVIDIA,幾乎有涉獵 chip design 的公司都可以找到類似的工作。典型的這類公司有 Arm、Apple、AMD。現在由於越來越多公司設計新的晶片用來加速 ML,以往專注於軟體的科技公司也需要相關的人才,例如 Google、Meta。現在也有新創在研發新的 ML 加速的晶片,也需要相關的人才。往軟體的方面,以上提到的公司不會只加速硬體,所以也都可以應徵。同時,現在越來越多公司需要用到 ML 的情況下,非常多的純軟公司也需要相關的人才來幫助加速 ML。這部分由於 GPU 仍是目前跑 ML 的主流,GPU Architecture、GPU Programming 會是非常重要的能力。
附錄
延伸 — 從Roofline Chart的角度看待瓶頸資源
除了本文中的不等式,我們也可以用運算強度和 Roofline Chart 的概念來幫助我們分析並找出瓶頸資源。
在本文找出瓶頸資源的不等式中,我們使用了一個比率
compute 工作量/memory 工作量
這個比率被稱為運算強度 (Arithmetic Intensity) ,意思是有多少個運算被用於每一個讀/寫的 byte。當這個強度越高,表示每讀進一個資料,處理器就花越多運算在這筆資料上,也就是說這個程式越來越仰賴 compute。當這個強度高過一個值之後,處理器運行這個程式的時間就會被 compute 這個資源所決定,這時 compute 就成為了瓶頸資源。我們稱這個情況為 compute bound。相反的,若運算強度低到處理器運行時間是被 memory 所決定時,memory 就是瓶頸資源,這個情況就是 memory bound。
接下來我們來看 Roofline Chart:
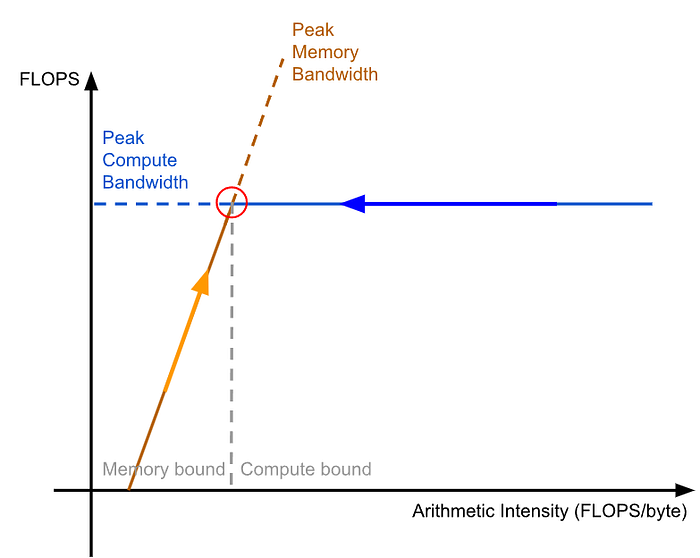
在這張圖中,x軸為運算強度,y軸為FLOPS,也就是 compute 的帶寬所用的單位。一個處理器中資源的帶寬是固定的,compute 的帶寬為圖中的藍色的線,memory 的帶寬為圖中咖啡色的線。當一個程式的運算強度在灰色虛線左側的時候,咖啡色線比藍色線還低,代表該程式被 memory 的帶寬決定了運行速度,這個狀況是 memory bound,memory就是瓶頸資源。同理,當運算強度在灰色虛線右側時,藍色線筆咖啡色線低,此時就是 compute bound,compute 就是瓶頸資源。
基於這點,現在我們來想想”減少瓶頸資源的工作量”這件事。假設我們有一個程式,它的瓶頸資源是 memory (也就是在 roofline chart 的左側),那麼為了加速這個程式,我們需要減少該程式的 memory 的工作量。假設 compute 的工作量不變,那麼不就表示我們相當於讓這個程式的運算強度增加了嗎?! 這就是 roofline chart 的橘色箭頭,我們透過增加運算強度來加速程式。同理,當一個程式的瓶頸資源是 compute 的時候,我們可以透過減少運算強度來加速程式,也就是圖中的藍色箭頭。當一個程式的運算強度在灰色虛線上時,此時 memory 和 compute 皆為瓶頸,兩者取得良好的平衡(紅色圈圈所在處),理想上這個程式正以它最快的速度運行!
參考
胡文美教授的 Heterogeneous Parallel Programming 課程。這是胡文美教授在 University of Illinois at Urbana Champaign (UIUC) 開的課程,這門課替我打下了堅實的加速 ML 的基礎。
